Showdown Leaderboard - LLMs
Real people. Real conversations. Real rankings.
Showdown ranks AI models based on how they perform in real-world use— not synthetic tests or lab settings. Votes are blind, optional, and organic, so rankings reflect authentic preferences.Methodology & Technical Report→0 promptsReal conversation prompts compared across models through pairwise votes.
0 usersFrom 80+ countries and 70+ languages, spanning all backgrounds and professions.
SEAL Leaderboard - LLMs
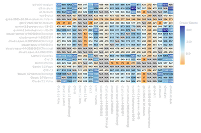
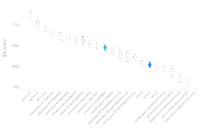
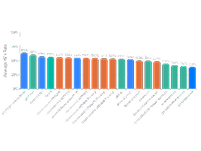
RANK ↑
MODEL ↑↓
VOTES ↑↓
SCORE ↑↓
1
gpt-5-chat
gpt-5-chat11212
1087.57
-4.38 +6.03
1
claude-sonnet-4-5-20250929
claude-sonnet-4-5-202509299400
1082.08
-4.57 +5.68
2
qwen3-235b-a22b-2507-v1
qwen3-235b-a22b-2507-v19100
1076.77
-3.67 +4.13
3
claude-opus-4-1-20250805
claude-opus-4-1-2025080512282
1072.51
-5.25 +4.57
5
claude-sonnet-4-20250514
claude-sonnet-4-2025051416947
1063.25
-4.2 +3.72
5
claude-sonnet-4-5-20250929 (Thinking)
claude-sonnet-4-5-20250929 (Thinking)9101
1058.47
-3.7 +5.23
5
claude-haiku-4-5-20251001
claude-haiku-4-5-202510014027
1055.31
-7.14 +6.67
7
gemini-3-pro-preview
gemini-3-pro-preview5302
1042.65
-6.55 +6.76
8
claude-opus-4-1-20250805 (Thinking)
claude-opus-4-1-20250805 (Thinking)10617
1042.63
-4.79 +5.23
8
gemini-2.5-pro
gemini-2.5-pro7080
1036.50
-6.32 +6.18
9
claude-haiku-4-5-20251001 (Thinking)
claude-haiku-4-5-20251001 (Thinking)3875
1031.01
-6.9 +6.81
10
claude-sonnet-4-20250514 (Thinking)
claude-sonnet-4-20250514 (Thinking)13829
1028.26
-3.25 +3.4
13
17747
1015.69
-3.18 +3.79
13
gemini-2.5-flash
gemini-2.5-flash7477
1011.01
-5.78 +6.22
15
llama4-maverick-instruct-basic
llama4-maverick-instruct-basic12425
1000.00
-5.25 +5.04
16
17534
985.55
-3.46 +4.31
17
deepseek-r1-0528
deepseek-r1-05287039
961.23
-6.32 +7.14
18
14112
945.21
-3.34 +4.64
* This model’s API does not consistently return Markdown-formatted responses. Since raw outputs are used in head-to-head comparisons, this may affect its ranking.